SC16 tutorial on OpenPOWER and GPUs (including a TALK)
On 14 November we held a tutorial on »Application Porting and Optimization on GPU-Accelerated POWER Architectures« during the Supercomputing Conference in Salt Lake City. The tutorial allowed me to travel to this largest conference on supercomputing-related topics for a first time. It was a busy, but great experience! I actually wrote a bit about it for the Jülich blog portal.
In the tutorial we spoke about
- the new POWER8NVL architecture, including its large bus to NVLink-equipped Tesla P100 GPUs,
- how to measure an application’s performance by means of hardware performance counters,
- how to use compiler flags to speed-up an application’s runtime - and what’s behind the flags,
- what’s new in the Tesla P100 GPUs,
- how to use OpenACC to run a program across a few of the GPU devices at once, and
- how an actual application can make use of the new features (especially the larger bus).
For three of the six parts we also had hand-ons where attendees of the tutorial could try out the various things taught. Since the POWER8NVL+P100 setup is so new, we actually had to use a machine in Jülich. Despite some general lag and initial WiFi problems in the room, this worked out surprisingly well. Every attendee downloaded an SSH key, signed a Usage Agreement, and exchanged it for the password to the key. Then they were good to go.
The organization of the tutorial was also an interesting study in international collaboration. We worked together with colleagues from Switzerland, the States, and India. Timezones nicely tripartite1, nearly at least. Also a peculiarity: We had to hand in all slides and material 2.5 months before the actual conference. Quite challenging when you speak about unreleased hardware…
In the end, the tutorial turned out quite well. In the evaluation, attendees gave us above average and close to best marks in all categories. Yay!
The slides and sets of source code are not available publicly, unfortunately. But here are mine! Slides, anyway.
I had the second talk (and subsequent first hands-on): »Performance Counters and Tools«. After the first talk, which introduced the POWER8 chip and related software infrastructure, I zoomed in on performance analysis with performance counters. This was a new topic for me as well it was assigned to me after a colleague left the institute. Although I worked with some performance counters before, my knowledge was not anywhere near the level of being able to knowledgeable teach others. So: Reading, testing, digging through documentation, finding use-cases. Detailed work, but as researchers this is in our job description after all.
In the end I had enough content to hold a 50 minute talk (easily). So much interesting stuff is to be told about performance counters! To cut it down to 30 minutes I moved a lot of the material into the appendix. Not ideal, but since the attendees receive the slides anyway, at least the work was not in vain this way.
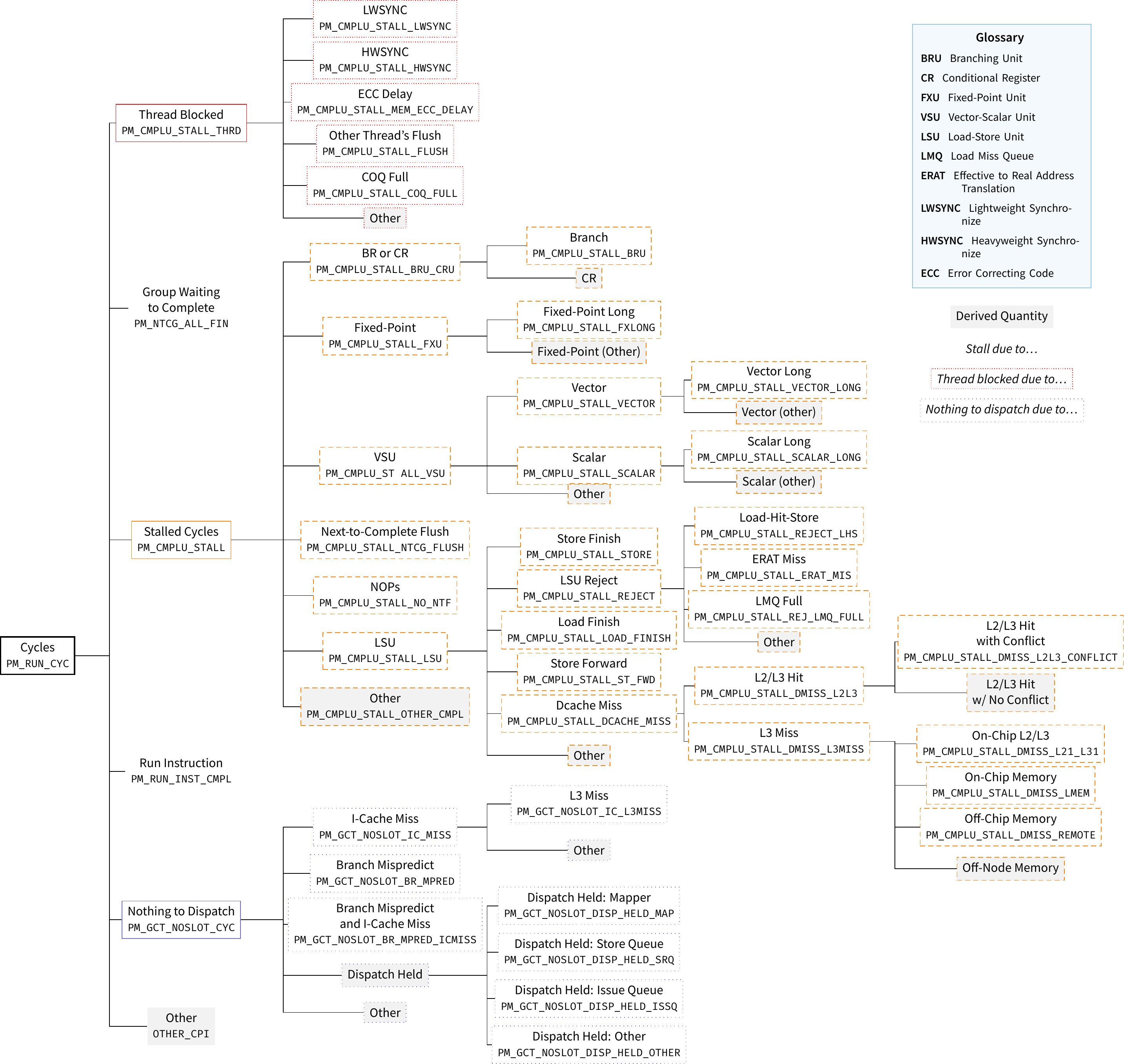
My hands-on afterwards focused on measuring stalls of a matrix multiplication. I use the number of stalls due to data cache misses (PMU code PM_CMPLU_STALL_DCACHE_MISS) once with a simple, un-optimized matrix-matrix multiplication and once with a matrix multiplication in which the inner two loops are interchanged. This reduces the amount of misses by two orders of magnitude and leads to a speed-up of about 20 %. The message was along the lines of: Stalls are bad, they can be reduced by clever code tuning; but their impact is also hidden by modern processor features.
If you’re interested, you can find the slides of the talk after the click. The slides I actually presented (with all the overlays) are here. For the time being, the source code for my hands-on is not available publicly. If you want them, give me a note.
I also remade IBM’s POWER8 CPI stack diagram into tree form. I like it better this way, although one could argue that the original table version also has its use. Here’s the PDF, a PNG, and also the TeX file.
-
I looked this up. It is supposed to mean divided by three, since India, Germany, and USA are roughly arranged in three equivalently distant time zones. ↩