SC17 Tutorial: Application Porting and Optimization on GPU-accelerated POWER Architectures
At last year’s Supercomputing Conference we held a full-day tutorial on Application Porting and Optimization on GPU-Accelerated POWER Architectures. And this year we did it again!
While last year’s tutorial was its first-ever incarnation, we were able to fine-tune the curriculum for this year a bit. The majority of the tutorial (e.g. the overall structure: CPU in the morning, GPU in the afternoon) was the same, but we changed quite a few details.
- The introductory lecture introduced the POWER/Minsky architecture in more detail. The speaker also introduced some theoretical concepts and explained the application we were using during the hands-on parts. Because…
- … we had one common example source code for each of the 3½ hands-on sessions. Based up on this, each session taught their respective examples.
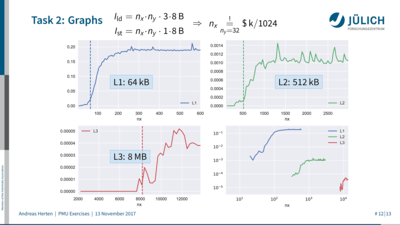
- My lecture on performance counters and measurement was reduced in time because the new introductory session took some of it. I trimmed down the content and moved lots of the stuff into the appendix. I re-did my hands-on session to focus on the new common source code – a Jacobi example – and also implemented more meaningful performance counters: Misses in L1/L2/L3 caches.
- The lecture on application optimization focused on platform-specific optimization, in addition to compiler flags. The speaker also used the common example and exploited the many cores of the processor by OpenMP.
- The GPU part was virtually untouched except for some updates. The speaker here used OpenACC to bring the application to a) a GPU and b) a number of GPUs.
- In the final presentation, the speaker presented some real-world examples using the Minsky machine and how they choose to utilize the fat node; also: Deep Learning.
 I think the changes to the content made the tutorial only more useful, as now one common theme is established. Also, we introduce modern programming models (OpenMP, OpenACC) and tools (PAPI, perf) through practical examples in passing. I like it.
I think the changes to the content made the tutorial only more useful, as now one common theme is established. Also, we introduce modern programming models (OpenMP, OpenACC) and tools (PAPI, perf) through practical examples in passing. I like it.
For my part on performance counters, I was able to measure the sizes of the processor’s three cache levels by counting the number of cache misses and relating them to the source code. A rather practical learning experience, IMHO.
The evaluation is not yet out for this one, but speaking to individual people after the sessions I heard good things. It’s yet to be decided if we submit another application to host the tutorial again next year.
You can find the different talks of the tutorial at the corresponding Indico site or on JuSER. My slides are also available locally and embedded further down. Also for this one, there’s a overlay-reduced version.